Continuous Variabls Are Needed for Regression
Categorical variables require special attention in regression analysis because, unlike dichotomous or continuous variables, they cannot by entered into the regression equation just as they are. Instead, they need to be recoded into a series of variables which can then be entered into the regression model. There are a variety of coding systems that can be used when recoding categorical variables. Regardless of the coding system you choose, the overall effect of the categorical variable will remain the same. Ideally, you would choose a coding system that reflects the comparisons that you want to make. For example, you may want to compare each level of the categorical variable to the lowest level (or any given level). In that case you would use a system called simple coding. Or you may want to compare each level to the next higher level, in which case you would want to use repeated coding. By deliberately choosing a coding system, you can obtain comparisons that are most meaningful for testing your hypotheses. Below is a table listing various types of contrasts and the comparison that they make.
| Name of contrast | Comparison made |
| Dummy Coding | Compares each level of a variable to the omitted (reference) level |
| Simple Coding | Compares each level of a variable to the reference level |
| Deviation Coding | Compares deviations from the grand mean. |
| Difference Coding | Compares levels of a variable with the mean of the previous levels of the variable. |
| Helmert Coding | Compare levels of a variable with the mean of the subsequent levels of the variable. |
| Orthogonal Polynomial Coding | Orthogonal polynomial contrasts. |
| Repeated Coding | Adjacent levels of a variable. |
| Special User-Defined Coding | User-defined contrast. |
We should note that some forms of coding make more sense with ordinal categorical variables than with nominal categorical variables. Below we will show examples using race as a categorical variable, which is a nominal variable. Because dummy coding compares the mean of the dependent variable for each level of the categorical variable to the mean of the dependent variable at for the reference group, it makes sense with a nominal variable. However, it may not make as much sense to use a coding scheme that tests the linear effect of race. As we describe each type of coding system, we note those coding systems with which it does not make as much sense to use a nominal variable.
Within SPSS there are two general commands that you can use for analyzing data with a continuous dependent variable and one or more categorical predictors, the regression command and the glm command. If using the regression command, you would create k-1 new variables (where k is the number of levels of the categorical variable) and use these new variables as predictors in your regression model. The values for these new variables will depend on coding system you choose. From this point we will refer to a coding scheme when used with the regression command as regression coding. Another method for analyzing categorical data would be to use the glm command and then you could use the /lmatrix or the /contrast subcommands to perform comparisons among the levels of the categorical variable. We will refer to this type of coding scheme as contrast coding. So, if you are using the regression command, be sure to choose the regression coding scheme and if you are using the glm command be sure to choose the contrast coding scheme.
The examples in this page will use dataset called hsb2.sav and we will focus on the categorical variable race, which has four levels (1 = Hispanic, 2 = Asian, 3 = African American and 4 = white) and we will use write as our dependent variable. Although our example uses a variable with four levels, these coding systems work with variables that have more categories or fewer categories. No matter which coding system you select, you will always have one fewer recoded variables than levels of the original variable. In our example, our categorical variable has four levels. We will therefore have three new variables. (A variable corresponding to the final level of the categorical variables would be redundant and therefore unnecessary.) Before considering any analyses, let's look at the mean of the dependent variable, write, for each level of race. This will help in interpreting the output from the analyses.
means tables = write by race.
| Cases | ||||||
|---|---|---|---|---|---|---|
| Included | Excluded | Total | ||||
| N | Percent | N | Percent | N | Percent | |
| writing score * RACE | 200 | 100.0% | 0 | .0% | 200 | 100.0% |
| RACE | Mean | N |
|---|---|---|
| hispanic | 46.4583 | 24 |
| asian | 58.0000 | 11 |
| african-amer | 48.2000 | 20 |
| white | 54.0552 | 145 |
| Total | 52.7750 | 200 |
DUMMY CODING
Perhaps the simplest and perhaps most common coding system is called dummy coding. It is a way to make the categorical variable into a series of dichotomous variables (variables that can have a value of zero or one only.) For all but one of the levels of the categorical variable, a new variable will be created that has a value of one for each observation at that level and zero for all others. In our example using the variable race, the first new variable (x1) will have a value of one for each observation in which race is Hispanic, and zero for all other observations. Likewise, we create x2 to be 1 when the person is Asian, and 0 otherwise, and x3 is 1 when the person is African American, and 0 otherwise. The level of the categorical variable that is coded as zero in all of the new variables is the reference level, or the level to which all of the other levels are compared. In our example, white is the reference level. You can select any level of the categorical variable as the reference level.
DUMMY CODING
| Level of race | New variable 1 (x1) | New variable 2 (x2) | New variable 3 (x3) |
| 1 (Hispanic) | 1 | 0 | 0 |
| 2 (Asian) | 0 | 1 | 0 |
| 3 (African American) | 0 | 0 | 1 |
| 4 (white) | 0 | 0 | 0 |
After creating the new variables, they are entered into the regression (the original variable is not entered), so we would enter x1 x2 and x3 instead of entering race into our regression equation and the regression output will include coefficients for each of these variables. The coefficient for x1 is the mean of the dependent variable for group 1 minus the mean of the dependent variable for the omitted group. In our example, the coefficient for x1 would be the mean of write for the Hispanic group minus the mean of write for the white group. Likewise, the coefficient for x2 would be the mean of write for the Asian group minus the mean of write for the white group, and the coefficient for x3 would be the mean of write for the African American group minus the mean of write for the white group.
Dummy Coding Using Regression
Below we show 2 methods for creating the dummy variables from the table above. In Method 1, we create a new variable (i.e., x1) that is set equal to zero. Then we change the value of this new variable to equal one if the level in the original (categorical) variable is one. We repeat this process for each new variable that we need to create. In Method 2, we use a "do-loop" to generate the new variables, which can be useful if your categorical variable has a large number of levels.
* Method 1 for creating dummy variables.
compute x1 = 0. if race = 1 x1 = 1. compute x2 = 0. if race = 2 x2 = 1. compute x3 = 0. if race = 3 x3 = 1. execute.
* Method 2 for creating dummy variables.
do repeat A=x1 x2 x3 /B=1 2 3. compute A=(x=B). end repeat. execute.
Below we show how to use the regression command to run the regression with write as the dependent variable and using the three dummy variables as predictors, followed by an annotated output.
regression /dep write /method = enter x1 x2 x3.
Variables Entered/Removed
| Model | Variables Entered | Variables Removed | Method | ||||
|---|---|---|---|---|---|---|---|
| 1 | X3, X2, X1(a) | . | Enter | ||||
| a All requested variables entered. | b Dependent Variable: writing score | ||||||
The table above shows which variables were entered into the regression equation. It also indicates that the method used was "enter", as opposed to other possible methods that could have been specified, such as backward, forward or stepwise. The table also indicates that all of the variables listed on the /method= subcommand were entered into the regression equation.
| Model | R | R Square | Adjusted R Square | Std. Error of the Estimate |
|---|---|---|---|---|
| 1 | .327(a) | .107 | .093 | 9.02511 |
| a Predictors: (Constant), X3, X2, X1 | ||||
| Model | Sum of Squares | df | Mean Square | F | Sig. | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Regression | 1914.158 | 3 | 638.053 | 7.833 | .000(a) | |||||||
| Residual | 15964.717 | 196 | 81.453 | ||||||||||
| Total | 17878.875 | 199 | |||||||||||
| a Predictors: (Constant), X3, X2, X1 | b Dependent Variable: writing score | ||||||||||||
The table above entitled Model Summary indicates that one model was tested, that 10.7% of the variance in the dependent variable is accounted for by the independent variable, and that 9.3% of the variance of the dependent variable is accounted for by the independent variable when the number of independent variables in the equation is taken into consideration. The standard error of the estimate is also given. The table entitled "ANOVA" gives the sum of squares and the degrees of freedom (in the column labeled "df") for the regression, the residual and the total (regression plus residual). The mean square is given for the regression and the residual, and the F-value and the associated p-value (in the column labeled Sig.) is displayed. These results indicate that the regression is statistically significant at the .05 alpha level. As you will see, the overall test of race is the same regardless of the coding system used.
| Unstandardized Coefficients | Standardized Coefficients | t | Sig. | |||
|---|---|---|---|---|---|---|
| Model | B | Std. Error | Beta | |||
| 1 | (Constant) | 54.055 | .749 | 72.122 | .000 | |
| X1 | -7.597 | 1.989 | -.261 | -3.820 | .000 | |
| X2 | 3.945 | 2.823 | .095 | 1.398 | .164 | |
| X3 | -5.855 | 2.153 | -.186 | -2.720 | .007 | |
| a Dependent Variable: writing score | ||||||
The table above gives the unstandardized coefficients for the regression equation (in the column labeled B) and the standard error (in the column labeled Std. Error). When using dummy coding, the constant is the mean of the omitted level of the categorical variable. The coefficient for x1 is the difference between the mean of the dependent variable for level 1 of race minus the mean of the dependent variable at level 4 of race (the reference level). Likewise, the coefficient for x2 and x3 is the mean of the dependent variable at that level of race minus the mean of the dependent variable for the reference level. The standardized coefficients are given in the column labeled Beta. The t-values and associated p-values are also given. The statistical significance of the constant is rarely of interest to researchers. The coefficients for x1 and x3 are statistically significant at the .05 (and .01) alpha level, while the coefficient for x2 is not. This indicates that level 1 of race (Hispanic) is significantly different from level 4 (white), and that level 3 (African American) is significantly different from level 4 (white).
Dummy Coding Using glm with /lmatrix
It is not possible to use dummy coding with glm with the /lmatrix command, so this is not illustrated here. If you wish this kind of comparison, then you should use Simple Effect Coding.
Dummy Coding Using glm with /contrast
It is not possible to use dummy coding with glm with the /contrast subcommand, so this is not illustrated here. If you wish this kind of comparison, then you should use Simple Effect Coding.
SIMPLE EFFECT CODING
The results of simple effect coding is very similar to dummy coding in that each group is compared to the reference group. In the example below, group 4 is the reference group and the first comparison compares group 1 to group 4, the second comparison compares group 2 to group 4, and the third comparison compares group 3 to group 4.
This example will show the three approaches that you can use for doing simple effect coding, 1) using the regress command, 2) GLM with /lmatrix subcommand (with one /lmatrix subcommand for each contrast), and 3) glm with the /contrast subcommand.
Simple Effect Coding Using Regression
The regression coding for simple effect coding is a bit more complex than dummy coding. In our example below, group 4 is the reference group and x1 compares group 1 to group 4, x2 compares group 2 to group 4, and x3 compares group 3 to group 4. For x1 the coding is 3/4 for group 1, and -1/4 for all other groups. Likewise, for x2 the coding is 3/4 for group 2, and -1/4 for all other groups, and for x3 the coding is 3/4 for group 3, and -1/4 for all other groups. Note that each new variable must sum to 0.
SIMPLE regression coding
| Level of race | New variable 1 (x1) | New variable 2 (x2) | New variable 3 (x3) |
| 1 (Hispanic) | .75 | -.25 | -.25 |
| 2 (Asian) | -.25 | .75 | -.25 |
| 3 (African American) | -.25 | -.25 | .75 |
| 4 (white) | -.25 | -.25 | -.25 |
Below we show how to create the variables x1, x2, and x3 from the table above in SPSS and to enter these variables into the regression model and an excerpt of the output showing the regression coefficients.
if race = 1 x1 = .75. if any(race,2,3,4) x1 = -.25. if race = 2 x2 = .75. if any(race,1,3,4) x2 = -.25. if race = 3 x3 = .75. if any(race,1,2,4) x3 = -.25. execute.
regression /dependent = write /method = enter x1 x2 x3.
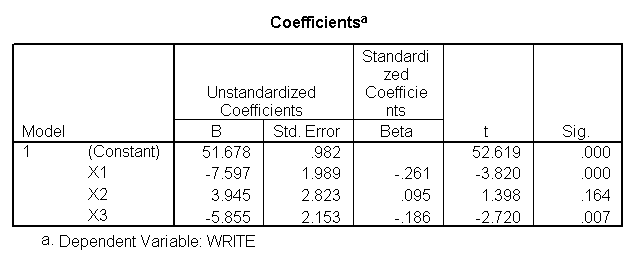
In the above example, the regression coefficient for x1 is the mean of write for level 1 (Hispanic) minus the mean of write for level 4 (white), and indeed if we compare this coefficient means of write by race we find 46.4583-54.0552 is -7.5969. Likewise, the regression coefficient for x2 is the mean of write for level 2 (Asian) minus the mean of write for level 4 (white), and the regression coefficient for x3 is the mean of write for level 3 (African American) minus the mean of write for level 4 (white).
Simple Effect Coding Using glm and /lmatrix
The table below shows simple effect coding using contrast coding, and you can see this coding is more straightforward. The first contrast compares group 1 to group 4, and group 1 is coded "1" and group 4 is coded "-1". Likewise, the second contrast compares group 2 to group 4 by coding group 2 "1" and group 4 "-1". As you can see with contrast coding, you can discern the meaning of the comparisons simply by inspecting the contrast coefficients. For example, looking at the contrast coefficients for c3 you can see that this compares group 3 to group 4.
SIMPLE effect contrast coding
| Level of race | New variable 1 (c1) | New variable 2 (c2) | New variable 3 (c3) |
| 1 (Hispanic) | 1 | 0 | 0 |
| 2 (Asian) | 0 | 1 | 0 |
| 3 (African American) | 0 | 0 | 1 |
| 4 (white) | -1 | -1 | -1 |
Below we show how to use the glm command with the /lmatrix subcommand to make the comparisons indicated in the table above. Note that a separate /lmatrix subcommand is required for each comparison.
glm write by race /lmatrix "group 1 versus group 4" race 1 0 0 -1 /lmatrix "group 2 versus group 4" race 0 1 0 -1 /lmatrix "group 3 versus group 4" race 0 0 1 -1.
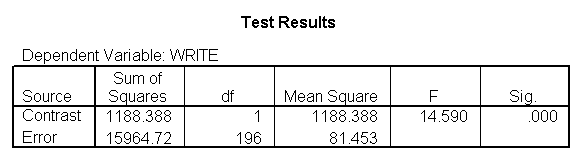
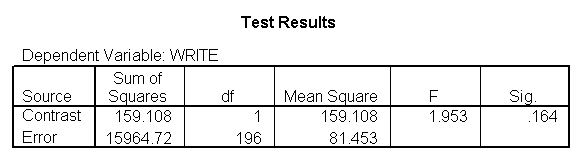
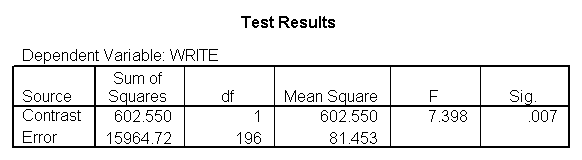
Below we show an excerpt of the output from this analysis, showing the 3 comparisons. Note that the Contrast Estimate for the first contrast is the mean of write for level 1 (Hispanic) minus the mean of write for level 4 (white), and indeed if we compare this estimate with the means of write by race we find 46.4583-54.0552 is -7.5969. Likewise, the second Contrast Estimate is the mean of write for level 2 (Asian) minus the mean of write for level 4 (white), and the third Contrast Estimate is the mean of write for level 3 (African American) minus the mean of write for level 4 (white). Note that the 3 Contrast Estimates correspond to the 3 coefficients from the regression analysis above.



Simple Effect Coding Using glm and /contrast
Since SPSS directly supports simple coding with the /contrast subcommand, we can simply include /contrast(race) = simple and SPSS will perform simple contrasts for us, as illustrated below.
glm write by race /contrast (race)=simple /print = parameter test(lmatrix).
Below we show an excerpted portion of the output focusing on the results of the simple contrasts.
The table below entitled "Contrast Coefficients (L' Matrix)" shows the coding scheme that was used for each comparison, and you can see that this matches the contrast coding we used in the prior section when we manually used the /lmatrix subcommand for the contrasts.. The table entitled "Contrast Results (K Matrix)" shows the results of the 3 contrasts. In our example, the difference between level 1 of race and level 4 of race is statistically significant. You will notice that the contrast estimate is the difference between the mean for the dependent variable for the omitted level minus the mean of the dependent variable for the first level. In other words, 46.4583 – 54.0552 = -7.597. The hypothesized value is zero (and is zero for all contrast tests). This means that the null hypothesis is that the coefficient equals zero, which is almost always the null hypothesis in which researchers are interested. The row labeled Difference (Estimate – Hypothesized) gives the difference between the contrast estimate and the hypothesized value. Because the null hypothesis is always zero, the contrast estimate and the difference between the contrast estimate and the null hypothesis are the same value. Therefore, you can either refer to the contrast estimate as being either statistically significant or not, or you can refer to the difference as being either statistically significant or not. In our example, the difference between level 2 of race and level 4 of race is not statistically significant, and the difference between level 3 of race and level 4 of race is statistically significant. If you compare the Contrast Estimates from below with those of the prior section and with the Coefficients from the regression command, you will see that these all match, illustrating that these three strategies are all forming the same comparisons.
| RACE Simple Contrast(a) | |||||||
|---|---|---|---|---|---|---|---|
| Parameter | Level 1 vs. Level 4 | Level 2 vs. Level 4 | Level 3 vs. Level 4 | ||||
| Intercept | 0 | 0 | 0 | ||||
| [RACE=1.00] | 1 | 0 | 0 | ||||
| [RACE=2.00] | 0 | 1 | 0 | ||||
| [RACE=3.00] | 0 | 0 | 1 | ||||
| [RACE=4.00] | -1 | -1 | -1 | ||||
| The default display of this matrix is the transpose of the corresponding L matrix. | a Reference category = 4 | ||||||
| Dependent Variable | |||
|---|---|---|---|
| RACE Simple Contrast(a) | writing score | ||
| Level 1 vs. Level 4 | Contrast Estimate | -7.597 | |
| Hypothesized Value | 0 | ||
| Difference (Estimate – Hypothesized) | -7.597 | ||
| Std. Error | 1.989 | ||
| Sig. | .000 | ||
| 95% Confidence Interval for Difference | Lower Bound | -11.519 | |
| Upper Bound | -3.675 | ||
| Level 2 vs. Level 4 | Contrast Estimate | 3.945 | |
| Hypothesized Value | 0 | ||
| Difference (Estimate – Hypothesized) | 3.945 | ||
| Std. Error | 2.823 | ||
| Sig. | .164 | ||
| 95% Confidence Interval for Difference | Lower Bound | -1.622 | |
| Upper Bound | 9.511 | ||
| Level 3 vs. Level 4 | Contrast Estimate | -5.855 | |
| Hypothesized Value | 0 | ||
| Difference (Estimate – Hypothesized) | -5.855 | ||
| Std. Error | 2.153 | ||
| Sig. | .007 | ||
| 95% Confidence Interval for Difference | Lower Bound | -10.101 | |
| Upper Bound | -1.610 | ||
| a Reference category = 4 | |||
| Source | Sum of Squares | df | Mean Square | F | Sig. |
|---|---|---|---|---|---|
| Contrast | 1914.158 | 3 | 638.053 | 7.833 | .000 |
| Error | 15964.717 | 196 | 81.453 |
DEVIATION CODING
This coding system compares the mean of the dependent variable for a given level to the mean of the dependent variable for the other levels of the variable. In our example below, the first comparison compares level 1 (Hispanics) to all 3 other groups, the second comparison compares level 2 (Asians) to the 3 other groups, and the third comparison compares level 3 (African Americans) to the 3 other groups.
Deviation Coding Using Regression
As you see in the example below, the regression coding is accomplished by assigning "1" to group 1 for the first comparison (since group 1 is the group to be compared to all others), a "1" to group 2 for the second comparison (since group 2 is to be compared to all others), and "1" to group 3 for the third comparison (since group 3 is to be compared to all others). Note that a "-1" is assigned to group 4 for all 3 comparisons (since it is the group that is never compared to the other groups) and all other values are assigned a 0. This regression coding scheme yields the comparisons described above.
DEVIATION regression coding
| Level of race | New variable 1 (x1) | New variable 2 (x2) | New variable 3 (x3) |
| Level 1 v. Mean | Level 2 v. Mean | Level 3 v. Mean | |
| 1 (Hispanic) | 1 | 0 | 0 |
| 2 (Asian) | 0 | 1 | 0 |
| 3 (African American) | 0 | 0 | 1 |
| 4 (white) | -1 | -1 | -1 |
Below we show how to create x1 x2 and x3 based on the table above and use them in the regression command.
if race = 1 x1 = 1. if any(race,2,3) x1 = 0. if race = 4 x1 = -1. if race = 2 x2 = 1. if any(race,1,3) x2 = 0. if race = 4 x2 = -1. if race = 3 x3 = 1. if any(race,1,2) x3 = 0. if race = 4 x3 = -1. execute. regression /dep write /method = enter x1 x2 x3.
Deviation Coding Using glm with /lmatrix
As you can see, contrast coding is much simpler. The first comparison that compares group 1 to groups 2, 3, 4 assigns 3/4 to group 1 and -1/4 to groups 2, 3, 4. Likewise, the second comparison that compares group 2 to groups 1, 3, 4 assigns 3/4 to group 2 and -1/4 to groups 1, 3, 4 and so forth for the third comparison. Note that you could substitute 3 for 3/4 and 1 for 1/4 and you would get the same test of significance, but the contrast coefficient would be different.
DEVIATION contrast coding
| Level of race | New variable 1 (c1) | New variable 2 (c2) | New variable 3 (c3) |
| Level 1 v. Mean | Level 2 v. Mean | Level 3 v. Mean | |
| 1 (Hispanic) | .75 | -.25 | -.25 |
| 2 (Asian) | -.25 | .75 | -.25 |
| 3 (African American) | -.25 | -.25 | .75 |
| 4 (white) | -.25 | -.25 | -.25 |
Below we illustrate how to use glm with the /lmatrix subcommand to perform the tests shown in the table above.
glm write by race /lmatrix "group 1 versus groups 1 2 and 3" race .75 -.25 -.25 -.25 /lmatrix "group 2 versus groups 1 3 and 4" race -.25 .75 -.25 -.25 /lmatrix "group 3 versus groups 1 2 and 4" race -.25 -.25 .75 -.25.
In the above examples, both the regression coefficient for x1 and the contrast estimate for c1 would be the mean of write for level 1 (Hispanic) minus the mean of write for levels 2, 3 and 4 combined. Likewise, the regression coefficient for x2 and the contrast estimate for c2 would be the mean of write for level 2 (Asian) minus the mean of write for levels 1, 3, and 4 combined.
Deviation Effect Coding Using glm with /contrast
Since SPSS directly supports deviation coding with the /contrast subcommand, we can simply include /contrast(race) = deviation and SPSS will perform deviation contrasts for us, as illustrated below.
glm write by race /contrast (race)=deviation /print = parameter test(lmatrix).
Interpretation
In the above examples, both the regression coefficient for x1 and the first contrast estimate would be the mean of write for level 1 (Hispanic) minus the mean of write for levels 2,3 and 4 combined. Likewise, the regression coefficient for x2 and the second contrast estimate would be the mean of write for level 2 (Asian) minus the mean of write for levels 1, 3, and 4 combined, and the regression coefficient for x3 and the third contrast estimate would be the mean of write for level 3 (African American) minus the mean of write for levels 1, 2, and 3 combined.
DIFFERENCE CODING
In this coding system, each level is compared to the mean of the previous levels. In our example, the first comparison compares the mean of the dependent variable for level 1 of race to the mean of the dependent variable for level 2 of race. The second comparison compares the mean of the dependent variable for both levels 1 and 2 of race with the mean of the dependent variable for level 3 of race, and the third comparison compares the mean of the dependent variable for levels 1,2 and 3 of race with the 4th level of race. Clearly, this coding system does not make much sense with our example of race because it is a nominal variable. However, this system is useful when the levels of the categorical variable are ordered in a meaningful way. For example, if we had a categorical variable in which work-related stress was coded as low, medium or high, then comparing the means of the previous levels of the variable would make more sense.
Difference Coding Using Regression
Below we see an example of regression coding. For the first comparison, where the first and second level are compared, x1 is coded -1/2 and 1/2 and the rest 0. For the second comparison, the values of x2 are coded -1/3 then -1/3 then 2/3 and then 0. Finally, for the 3rd comparison, the values of x3 are coded -1/4 -1/4 -/14 and then 3/4.
DIFFERENCE regression coding
| New variable 1 (x1) | New variable 2 (x2) | New variable 3 (x3) | |
| Level 2 v. Level 1 | Level 3 v. Previous | Level 4 v. Previous | |
| 1 (Hispanic) | -.5 | -.333 | -.25 |
| 2 (Asian) | .5 | -.333 | -.25 |
| 3 (African American) | 0 | .666 | -.25 |
| 4 (white) | 0 | 0 | .75 |
Below we show how to use the above coding with the regression command.
if race = 1 x1 = -.5. if race = 2 x1 = .5. if any(race,3,4) x1 = 0. if any(race,1,2) x2 = -.333. if race = 3 x2 = .667. if race = 4 x2 = 0. if any(race,1,2,3) x3 = -.25. if race = 4 x3 = .75. execute. regression /dep write /method = enter x1 x2 x3.
Difference Coding Using glm with /lmatrix
For contrast coding, we see that the first comparison comparing groups 1 and 2 are coded -1 and 1 to compare these groups, and 0 otherwise. The second comparison comparing groups 1,2 with group 3 are coded -.5 -.5 1 and 0, and the last comparison comparing groups 1,2,3 with group 4 are coded -.333 -.333 -.333 and 1.
DIFFERENCE contrast coding
| New variable 1 (c1) | New variable 2 (c2) | New variable 3 (c3) | |
| Level 2 v. Level 1 | Level 3 v. Previous | Level 4 v. Previous | |
| 1 (Hispanic) | -1 | -.5 | -.333 |
| 2 (Asian) | 1 | -.5 | -.333 |
| 3 (African American) | 0 | 1 | -.333 |
| 4 (white) | 0 | 0 | 1 |
Below we show how to perform these comparisons using glm with the /lmatrix subcommand. Note the use of fractions on the /lmatrix subcommand below. As mentioned above, you need to use numbers that sum to zero, such as 1/3 + 1/3 + 1/3 – 1. You cannot use .333 instead of 1/3: SPSS will give an error message and fail to calculate the contrast coefficient. The problem is that .333 + .333 + .333 – 1 is not sufficiently close to zero.
glm write by race /lmatrix "group 2 versus group 1" race -1 1 0 0 /lmatrix "group 3 versus groups 1 and 2" race -.5 -.5 1 0 /lmatrix "group 4 versus groups 1 2 and 3" race -1/3 -1/3 -1/3 1.
Difference Coding Using glm with /contrast
Since SPSS directly supports difference coding with the /contrast subcommand, we can simply include /contrast(race) = difference and SPSS will perform difference contrasts for us, as illustrated below.
glm write by race /contrast (race)=difference /print = test(lmatrix).
Interpretation
In the above examples, both the regression coefficient for x1 and the contrast estimate for c1 would be the mean of write for level 1 (Hispanic) minus the mean of write for level 2 (Asian). Likewise, the regression coefficient for x2 and the contrast estimate for c2 would be the mean of write for levels 1 and 2 combined minus the mean of write for level 3. Finally, the regression coefficient for x3 and the contrast estimate for c3 would be the mean of write for levels 1, 2 and 3 combined minus the mean of write for level 4.
HELMERT CODING
Helmert coding is the mirror image of difference coding: instead of comparing each level of categorical variable to the mean of the previous level, it is compared to the mean of the subsequent levels. Hence, the first contrast compares the mean of the dependent variable for level 1 of race with the mean of all of the subsequent levels of race (levels 2, 3, and 4), the second contrast compares the mean of the dependent variable for level 2 of race with the mean of all of the subsequent levels of race (levels 3, and 4), and the third contrast compares the mean of the dependent variable for level 3 of race with the mean of all of the subsequent levels of race (level 4). However, this type of coding is useful in situations where the levels of the categorical variable are ordered say, from lowest to highest, or smallest to largest, etc.
Helmert Coding Using Regression
Below we see an example of regression coding, and you can see that the coding is simply the mirror image of the difference coding. For the first comparison (comparing 1 with 2, 3, and 4) the codes are 3/4 and -1/4 -1/4 -1/4. The second comparison compares groups 2 with 3 and 4 and is coded 0 2/3 -1/3 -1/3. The third comparison compares levels 3 and 4 and is coded 0 0 1/2 -1/2.
HELMERT regression coding
| Level of race | New variable 1 (x1) | New variable 2 (x2) | New variable 3 (x3) |
| Level 1 v. Later | Level 2 v. Later | Level 3 v. Later | |
| 1 (Hispanic) | .75 | 0 | 0 |
| 2 (Asian) | -.25 | .666 | 0 |
| 3 (African American) | -.25 | -.333 | .5 |
| 4 (white) | -.25 | -.333 | -.5 |
Below we show how to perform these tests using the regression command.
if race = 1 x1 = .75. if any(race,2,3,4) x1 = -.25. if race = 1 x2 = 0. if race = 2 x2 = .667. if any(race,3,4) x2 = -.333. if any(race,1,2) x3 = 0. if race = 3 x3 = .5. if race = 4 x3 = -.5. execute. regression /dep write /method = enter x1 x2 x3.
Helmert Coding Using glm with /lmatrix
For contrast coding, we see that the first comparison comparing group 1 with groups 2, 3 and 4 is coded 1 -.333 -.333 -.333 reflecting the comparison of group 1 vs. all other groups. The second comparison is coded 0 1 -.5 -.5 reflecting that it compares group 2 with groups 3 and 4. The third comparison is coded 0 0 1 -1 reflecting that group 3 is compared to group 4.
HELMERT contrast coding
| Level of race | New variable 1 (c1) | New variable 2 (c2) | New variable 3 (c3) |
| Level 1 v. Later | Level 2 v. Later | Level 3 v. Later | |
| 1 (Hispanic) | 1 | 0 | 0 |
| 2 (Asian) | -.333 | 1 | 0 |
| 3 (African American) | -.333 | -.5 | 1 |
| 4 (white) | -.333 | -.5 | -1 |
Below we show how to perform these comparisons using glm with the /lmatrix subcommand.
glm write by race /lmatrix "group 1 versus groups 2 3 and 4" race 1 -1/3 -1/3 -1/3 /lmatrix "group 2 versus groups 3 and 4" race 0 1 -.5 -.5 /lmatrix "group 3 versus group 4" race 0 0 1 -1.
Helmert Coding Using glm with /contrast
Since SPSS directly supports helmert coding with the /contrast subcommand, we can simply include /contrast(race) = helmert and SPSS will perform Helmert contrasts for us, as illustrated below.
glm write by race /contrast (race)=helmert /print = test(lmatrix).
Interpretation
In the above examples, both the regression coefficient for x1 and the contrast estimate for c1 would be the mean of write for level 1 (Hispanic) vs all subsequent levels (levels 2, 3 and 4). Likewise, the regression coefficient for x2 and the contrast estimate for c2 would be the mean of write for level 2 minus the mean of write for levels 3 and 4. Finally, the regression coefficient for x3 and the contrast estimate for c3 would be the mean of write for level 3 minus the mean of write for level 4.
ORTHOGONAL POLYNOMIAL CODING
Orthogonal polynomial coding is a form trend analysis in that it is looking for the linear, quadratic and cubic trends in the categorical variable. This type of coding system should be used only with an ordinal variable in which the levels are equally spaced. An example of such a variable might be income, or education. Although it does not make much sense to look at linear, quadratic and cubic effects of race, we will perform these analyses nonetheless to simply illustrate how to do this form of coding.
Orthogonal Polynomial Coding with Regression
Below we show the coding that would be used for obtaining the linear, quadratic and cubic effects for a 4 level categorical variable. If you have more (or fewer) levels of your variable, you could consult a statistics textbook for a table of orthogonal polynomials.
POLYNOMIAL
| Level of race | Linear (x1) | Quadratic (x2) | Cubic (x3) |
| 1 (Hispanic) | -.671 | .5 | -.224 |
| 2 (Asian) | -.224 | -.5 | .671 |
| 3 (African American) | .224 | -.5 | -.671 |
| 4 (white) | .671 | .5 | .224 |
Below we show how to create the variables for the regression analysis based on the above table and enter them into the regression command.
if race = 1 x1 = -.671. if race = 2 x1 = -.224. if race = 3 x1 = .224. if race = 4 x1 = .671. if race = 1 x2 = .5. if race = 2 x2 = -.5. if race = 3 x2 = -.5. if race = 4 x2 = .5. if race = 1 x3 = -.224. if race = 2 x3 = .671. if race = 3 x3 = -.671. if race = 4 x3 = .224. execute. regression /dep write /method = enter x1 x2 x3.
Orthogonal Polynomial Coding using glm with /lmatrix
Because these comparisons are orthogonal (uncorrelated), the regression coding is the same as the contrast coding, so the example below shows how to use glm with the /lmatrix subcommand to obtain the tests of the linear, quadratic, and cubic effect of race.
glm write by race /lmatrix "linear" race -.671 -.224 .224 .671 /lmatrix "quadratic" race .5 -.5 -.5 .5 /lmatrix "cubic" race -.224 .671 -.671 .224.
Orthogonal Polynomial Coding using glm with /contrast
Since SPSS directly supports orthogonal polynomial coding with the /contrast subcommand, we can simply include /contrast(race) = polynomial and SPSS will perform orthogonal polynomial contrasts for us, as illustrated below.
glm write by race /contrast (race)=polynomial /print = test(lmatrix).
Interpretation
To calculate the contrast estimates for these comparisons, you need to multiply the code used in the new variable by the mean for the dependent variable for each level of the categorical variable, and then sum the values. For example, the code used in x1 for level 1 of race is -.671 and the mean of write for level 1 is 46.4583. Hence, you would multiply -.671 and 46.4583 and add that to the product of the code for level 2 of x1 and its mean, and so on. To obtain the contrast estimate for the linear contrast, you would do the following: -.671*46.4583 + -.224*58 + .224*48.2 + .671*54.0552 = 2.905 (with rounding error). This result is not statistically significant at the .05 alpha level, but it is close. The quadratic component is also not statistically significant, but the cubic one is. This suggests that, if the mean of the dependent variable plotted against race, the line would tend to have two bends. As noted earlier, this type of coding system does not make much sense with a nominal variable such as race.
REPEATED EFFECT CODING
In this coding system, the mean of the dependent variable for one level of the categorical variable is compared to the mean of the dependent variable for the adjacent level. In our example below, the first comparison compares the the mean of write for level 1 with the mean of write for level 2 of race (Hispanics minus Asians). The second comparison compares the mean of write for level 2 minus level 3, and the third comparison compares the mean of write for level 3 minus level 4. This type of coding may be useful with either a nominal or an ordinal variable.
Repeated Coding using Regression
Below we see an example of regression coding. For the first comparison, where the first and second level are compared, x1 is coded -3/4 for level 1 and the rest -1/4. For the second comparison where level 2 is compared with level 3, x2 is coded 1/2 1/2 -1/2 -1/2, and for the third comparison where level 3 is compared with level 4, x3 is coded 1/4 1/4 1/4 and -3/4.
REPEATED regression
| Level of race | New variable 1 (x1) | New variable 2 (x2) | New variable 3 (x3) |
| Level 1 v. Level 2 | Level 2 v. Level 3 | Level 3 v. Level 4 | |
| 1 (Hispanic) | .75 | .5 | .25 |
| 2 (Asian) | -.25 | .5 | .25 |
| 3 (African American) | -.25 | -.5 | .25 |
| 4 (white) | -.25 | -.5 | -.75 |
Below we show how to create x1 x2 and x3 and how to enter these using the regression command.
if race = 1 x1 = .75. if any(race,2,3,4) x1 = -.25. if any(race,1,2) x2 = .5. if any(race,3,4) x2 = -.5. if any(race,1,2,3) x3 = .25. if race = 4 x3 = -.75. execute. regression /dep write /method = enter x1 x2 x3.
Repeated Coding using GLM with /lmatrix
For contrast coding, the coding more naturally reflects the comparisons being made. The first comparison is coded 1 -1 0 0 reflecting that group 1 is compared to group 2. The second comparison is coded 0 1 -1 0 reflecting that group 2 is compared to group 3, and the third comparison is coded 0 0 1 -1 reflecting that group 3 is compared with group 4.
REPEATED contrast coding
| Level of race | New variable 1 (c1) | New variable 2 (c2) | New variable 3 (c3) |
| Level 1 v. Level 2 | Level 2 v. Level 3 | Level 3 v. Level 4 | |
| 1 (Hispanic) | 1 | 0 | 0 |
| 2 (Asian) | -1 | 1 | 0 |
| 3 (African American) | 0 | -1 | 1 |
| 4 (white) | 0 | 0 | -1 |
Below we show how to use the glm command with /lmatrix to form the comparisons illustrated above.
glm write by race /lmatrix "group 1 versus group 2" race 1 -1 0 0 /lmatrix "group 2 versus group 3" race 0 1 -1 0 /lmatrix "group 3 versus group 4" race 0 0 1 -1.
Repeated Coding using glm with /contrast
Since SPSS directly supports repeated coding with the /contrast subcommand, we can simply include /contrast(race) = repeated and SPSS will perform repeated contrasts for us, as illustrated below.
glm write by race /contrast (race)=repeated /print = test(lmatrix).
With this coding system, adjacent levels of the categorical variable are compared. Hence, the mean of the dependent variable at level 1 is compared to the mean of the dependent variable at level 2: 46.4583 – 58 = -11.542, which is statistically significant. For the comparison between levels 2 and 3, the calculation of the contrast coefficient would be 58 – 48.2 = 9.8, which is also statistically significant. Finally, comparing levels 3 and 4, 48.2 – 54.0552 = -5.855, a statistically significant difference. One would conclude from this that each adjacent level of race is statistically significantly different.
SPECIAL USER-DEFINED CODING SYSTEM
While we have seen a wide variety of contrasts so far, this does not even begin to enumerate all of the contrasts that are possible. For example, say that we wish to make the following 3 comparisons — 1) level 1 to level3, 2) level 2 to levels 1 and 4, and 3) levels 1 and 2 to levels 3 and 4. Let's start by showing how you can do this via glm with contrast coding.
Special Coding System Using glm with /lmatrix
Based on the comparisons that are to be made, we can create the contrast coding as shown below. The first contrast compares levels 1 and 3, so we code that 1 0 -1 0 to reflect that we want to compare level 1 with level 3. The second contrast is coded -.5 1 0 -.5 to reflect the comparison of level 2 with levels 1 and 4. The third contrast is coded .5 .5 -.5 -.5 to reflect that levels 1 and 2 are compared to levels 3 and 4.
Special User Defined contrast coding
| Level of race | New variable 1 (c1) | New variable 2 (c2) | New variable 3 (c3) |
| level 1 to level3 | level 2 to levels 1 and 4, and 3 | levels 1 and 2 to levels 3 and 4 | |
| 1 (Hispanic) | 1 | -.5 | .5 |
| 2 (Asian) | 0 | 1 | .5 |
| 3 (African American) | -1 | 0 | -.5 |
| 4 (white) | 0 | .-5 | -.5 |
Below we show how to perform these comparisons with glm using the /lmatrix command.
glm write by race /lmatrix "compare group 1 to group 3" race 1 0 -1 0 /lmatrix "compare group 2 to groups 1 and 4" race -.5 1 0 -.5 /lmatrix "compare groups 1 and 2 to groups 3 and 4" race .5 .5 -.5 -.5.
Special Coding System Using glm with /contrast
SPSS does not have a ready made coding scheme for this set of comparisons, but we can use the /contrast subcommand with special to supply our own contrasts. Note that the contrasts are listed out in 3 groups separated by commas to help you see each set of comparisons.
glm write by race /contrast (race)=special(1 0 -1 0, -.5 1 0 -.5, .5 .5 -.5 -.5) /print = test(lmatrix).
Special Coding System Using Regression
We were able to translate the comparisons we wanted to make into contrast codings. If we know the contrast coding system, then we can convert that into a regression coding system using the SPSS program as shown below.
matrix. compute c = { 1, -.5, .5 ; 0, 1, .5 ; -1, 0, -.5 ; 0, -.5, -.5 }. compute x = c*inv( t(c)*c ). print x . end matrix. We placed the 3 contrast codings we wanted into the matrix c and then performed a set of matrix operations on c yielding the matrix x and then we display x using the print command. Below we see the output from this.
X -.500000000 -1.000000000 1.500000000 .500000000 1.000000000 -.500000000 -1.500000000 -1.000000000 1.500000000 1.500000000 1.000000000 -2.500000000
This converted the contrast coding into the regression coding that we would need for running this analysis with the regress command. Below, we use if commands to create x1 x2 and x3 according to the coding shown above and then enter that into the regression analysis.
if race = 1 x1 = -0.5. if race = 2 x1 = .5. if race = 3 x1 = -1.5. if race = 4 x1 = 1.5.
if race = 1 x2 = -1. if race = 2 x2 = 1. if race = 3 x2 = -1. if race = 4 x2 = 1. if race = 1 x3 = 1.5. if race = 2 x3 = -.5. if race = 3 x3 = 1.5. if race = 4 x3 =-2.5. execute.
regression /dep write /method = enter x1 x2 x3.
Here is a shortcut to save typing all of the compute commands. This assumes that the variable race is coded 1 2 3 4.
get file = "c:\spss\hsb2.sav". sort cases by race. save outfile = "c:\temp\race.sav". matrix. compute c = { 1, -.5, .5 ; 0, 1, .5 ; -1, 0, -.5 ; 0, -.5, -.5 }. compute x = c*inv( t(c)*c ). save x /outfile=* /var=x1 x2 x3 end matrix. compute race = $CASENUM. execute. match files /table=* /file="c:\temp\race.sav" /by race. execute. regression /dep write /method = enter x1 x2 x3.
Interpretation
The first comparison of the mean of the dependent variable for level 1 to level 3 of the categorical variable was not statistically significant, while the comparison of the mean of the dependent variable for level 2 to that of levels 1 and 4 was. The comparison of the mean of the dependent variable for levels 1 and 2 to that of levels 3 and 4 was not statistically significant.
Source: https://stats.oarc.ucla.edu/spss/faq/coding-systems-for-categorical-variables-in-regression-analysis-2/
{kind=link}
Post a Comment for "Continuous Variabls Are Needed for Regression"